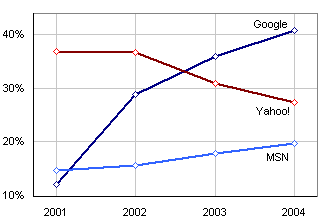
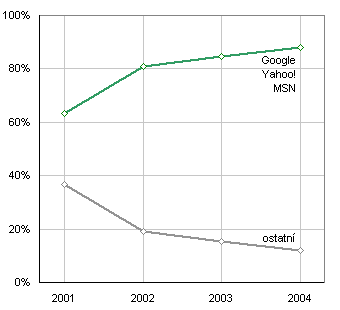
Musím říct, že vzhled stránek má pro mě poměrně velký význam. Dneska změnil vzhled web z nejwebovatějších – Google.
Titulní stránka je ještě více graficky odlehčená. To samé platí i pro stránky s výsledky vyhledávání. Tmavomodrou barvu vodorovných lišt vystřídala světlemodrá barva s tenkou ohraničující tmavě modrou linkou. Horní lišta neobsahuje navigaci Web | Obrázky | Skupiny | Adresář
– ta se přesunula na stránce úplně nahoru. Z horních pozic starého designu se až dolů propadly volby Výběr jazyka
a Tipy pro vyhledávání
. Pokročilé vyhledávání
a Nastavení
si našlo místo vpravo od tlačítka Hledej
, které se původně jmenovalo Vyhledat Googlem
.
Cítím patrnou snahu po dalším zjednodušení. Pořád ale přetrvávájí mírné nejednotnosti. Např. tlačítko pro vyhledávání na titulce nese nápis Vyhledat Googlem
(čím bych na Google hledal jiným?) a ve výsledcích Hledej
. Vedle pole pro vyhledávání na titulce chybí oproti stejnému poli na stránce s výsledky odkaz Výběr jazyka
(je dole). To jsou ale opravdu drobnosti.
Co mě ale udivuje, je přístup autorů HTML kódu. Web není validní. Stačí letmý pohled a vyplavou začátečnické chyby, např.:
- hodnoty atributů nejsou uzavřené v uvozovkách,
- …,
- atd.
Chyb je samozřejmě(?) víc. Kdyby měl dokument DTD, možná bych mohl napsat číslo mezi 20 – 57, ale takto opravdu nevím.
Související